Source code can be found at Github
The GameStop saga.
It captivated the world and reflected the remarkable shift in trading dynamics. Namely, the rise of day trading and the enormous online communities that, during the heat of the COVID-19 pandemic, brought many people from the edge to the center of attention in the financial world.
The GameStop Corporation, a struggling brick-and-mortar video game retailer, found itself at the center of this extraordinary story. Individual investors, often appearing in various online communities but most particularly within Reddit’s WallStreetBets community, sought to challenge the traditional dominance that institutional investors and hedge funds ordinarily have on the market. This dominance resulted in the gradual decline of GameStop stock as the institutional investors betted on the downfall of the stock. However, these online communities believed that this perception was as a result of unfair manipulation and sought to upset the status quo by purchasing the GameStop stock en masse. What resulted, was an exponential increase in stock price as short sellers were squeezed out and the online communities celebrated.
While the high did not last the entire sage showcased the power that individual investors can have on the financial markets. Although, looking at the hub of new-wave investors, WallStreetBets, while influential, they do not possess the same level of backing, infrastructure or capital as institutional firms. Nevertheless, the Gamestop sage has highlighted the need for tools and platforms that enable investors to analyse stocks and gain insights into collective sentiments. Understanding the perception of market participants valuable indications of potential market directions can be unveiled. By leveraging sentiment analysis and sentiment tracking tools, investors can navigate the evolving landscape more effectively and make informed decisions. This is where StockTrend comes into the fray.
Overview
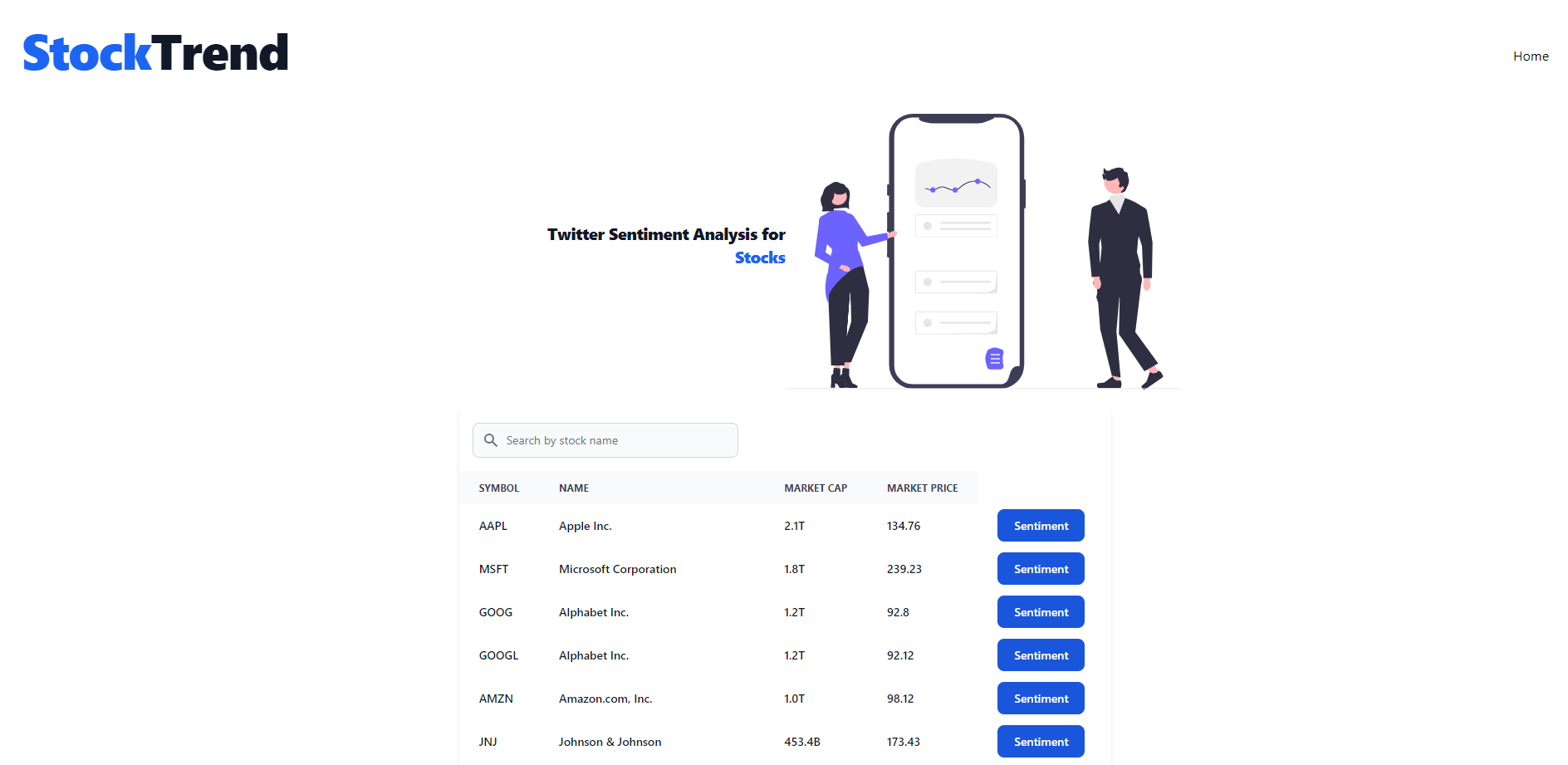
To put it in a sentence, the general idea of StockTrend, is to provide a method to show current stock market sentiments based on real-time data. Twitter was chosen as the source of real-time data as it offers a vast and diverse user bases, encompassing traders, investors and enthusiasts from all walks of life and as such we increase our likelihood we represent the total opinion of the collective. Also, as one of the largest social media sources on the planet, it is a premium social media for reacting to global events as they unfold, providing a timely understanding to specific and marco stock movements.
(It is also important to note that unfortunately as I was working on this project Twitter removed access to both tweet searching and filtered stream on it’s free tier and as such the website provides little functionality and testing was done at minimal levels)
Tech Stack
As with any web-based project there is a front-end and back-end and of course the methods to which we communicate with one another. Honestly, I do not think choices particularly matter for specific technologies as any gains a certain tech stack may other would almost certainly be counteracted by a subpar implementation but as I am trying to learn more about various web technologies I try to pick varied technologies for each project. To quickly run through it, SvelteKit was used for the entirety of the website, so it handles requesting data from our backend data stores. Python was chosen to query our machine learning model in order to generate sentiment values and Node.js was used as part of the backend in order to interact with the model and to interact with the Twitter API .
Architecture
Back-End
As of the current moment, only data storage is present on the cloud and the processes involving the Twitter API and machine learning model are both hosted locally on my own machine. Primarily, as this was more efficient for me to test however in future deploying these services as serverless components would be an attractive avenue to tackle. But, as we will see later deploying these models would turn out to be an expensive avenue to keep running.
Twitter API
For the idea as a whole to come to fruition, a lot of my focus was placed on tackling the Twitter API. Generally there were two avenues of approach, a staggered or a continuous approach. The staggered approach involves searching for tweets that have recently occurred over some timeframe while the continuous approach uses the Twitter API’s filtered stream endpoint. This endpoint provides similar functionality to tweet searching with the use of tweet searching however gives the added benefits of having unmodified rules and less limits on requests required. However this approach involves a far heavier computational load in handling real-time data. As such an efficient query should be devised that removes irrelevant tweets, and also ensuring that the tweets are original and comes from authentic users. It become clear when running the model that a large majority of tweets about stocks are bot tweets that spam hashtags and repeat the same talking points. However, while testing, my access to tweet searching was removed as part of a price restructuring and so adjusting the rules was not possible.
Also, there was the constraint of having five rules per stream and since I wanted to analyse all stocks on the Nasdaq, queries had to be combined in order to facilitate a larger number of stocks. Each query contained a list of stock tickers, as tweets involving investors usually contain the ticker symbol of that stock, and also the full name of the stocks.
What resulted was a steady stream of data however this data, although relevant had to be separated so that each tweet talked about a certain stock. This was a fairly simple process as stocks were only collected if they contained a certain ticker or name and as such it was a matter of giving the tweet the tag that triggered the matching query. Of course, there is the matter of tweets involving multiple stocks and this just resulted in the stock receiving multiple tags. With more advanced queries that inferred meaning from a tweet and may have involved misspelled stock names then we would have to become with a more robust method of giving tweets tags, such as fuzzy string matching.
Data Storage
Amazon s3 buckets provided a simple solution. Each bucket can be referenced some key and as such can be referenced as ${stockName}/date/. for uploading data and also for retrieval of data for either processing or display.
Data Processing
Now that we can gather relevant tweets with appropriate tags, we can now actually determine the sentiment to be associated with each tweet. The RoBERTa large model was gathered from huggingface to be used for this process. I may write a blog talking about this model but generally it is part of the BERT (Bidirectional Encoder Representation from Transformers) family of language models. BERT is based fundamentally on the encoder portion of the transformer model with an innovative training layer in order to efficiently represent contexts, however it differs from traditional RNNs as it uses an entire sentence at once rather than seeing words one after another, hence the model is bidirectional. BERT is specifically trained by masking words in the input and asking the model to predict the masked words and so the model is able to learn an internal representation of English. As such it is useful for us as we can tune the model to perform tasks such as sentiment analysis. This was done using this kaggle dataset in a supervised manner
With the model trained and ready to make predictions, an API is used to interact with the model in order to separate processes and as such at regular intervals tweets can be collected from the current bucket and processed, ready for display on the website.
Website
As mentioned earlier, StockTrend was made using SvelteKit, a framework that harness the UI features of svelte while also featuring the use of a router and server-side functionality in order to allow the retrieval and display of data from firestore. Data arrives in the form of JSON and so it is an easy transformation to convert the JSON data into an attractive format. On the home page a general list of data surrounding each stock is revealed with links onto specific webpages for each stock. Each stock then contains the results from the machine learning model as well as displaying the tweets that resulted in the specific result. This involved interacting with the Twitter API in order to display tweets in a manner that conforms to the style guide Twitter. Generally when doing the website I tried to implement a simple yet usable design.
Lessons Learnt
Throughout the project I have honed my skills of full-stack development, from the implementation of models onto the front-end experience of an end user. However, there are other aspects which I have specifically found important to appreciate while undertaking this project. First of all, data quality is a terribly important aspect of any data-based application. In particular, devising clear rules that allow authentic and truthful crowdsourced data to be gathered and to limit the number of spam related or erroneous tweets creates an effective and worthwhile application. As well as this, the development of a friendly user experience is crucial for providing a seamless experience that allows users to truly harness the power of any data collected. Finally, the implementation of models should be done in a manner that maximises the accuracy of any model that uses user data to power predictions while also interacting with a new API brought challenges that means having to conform with another cohort’s rules.
Conclusions
In conclusion, the development journey of creating a stock sentiment analysis website that harnesses Twitter data has illuminated the power and potential of social media in shaping market insights. By leveraging real-time data and sentiment analysis techniques, such a website offers investors a unique perspective on the sentiment surrounding stocks. Ultimately, the development of a stock sentiment analysis website serves as a testament to the transformation potential of social media and technology in the financial landscape. By embracing the insights gleaned from social media data and sentiment analysis, investors can make more informed decisions, navigate market uncertainties, and adapt to evolving trends.
See you next time,